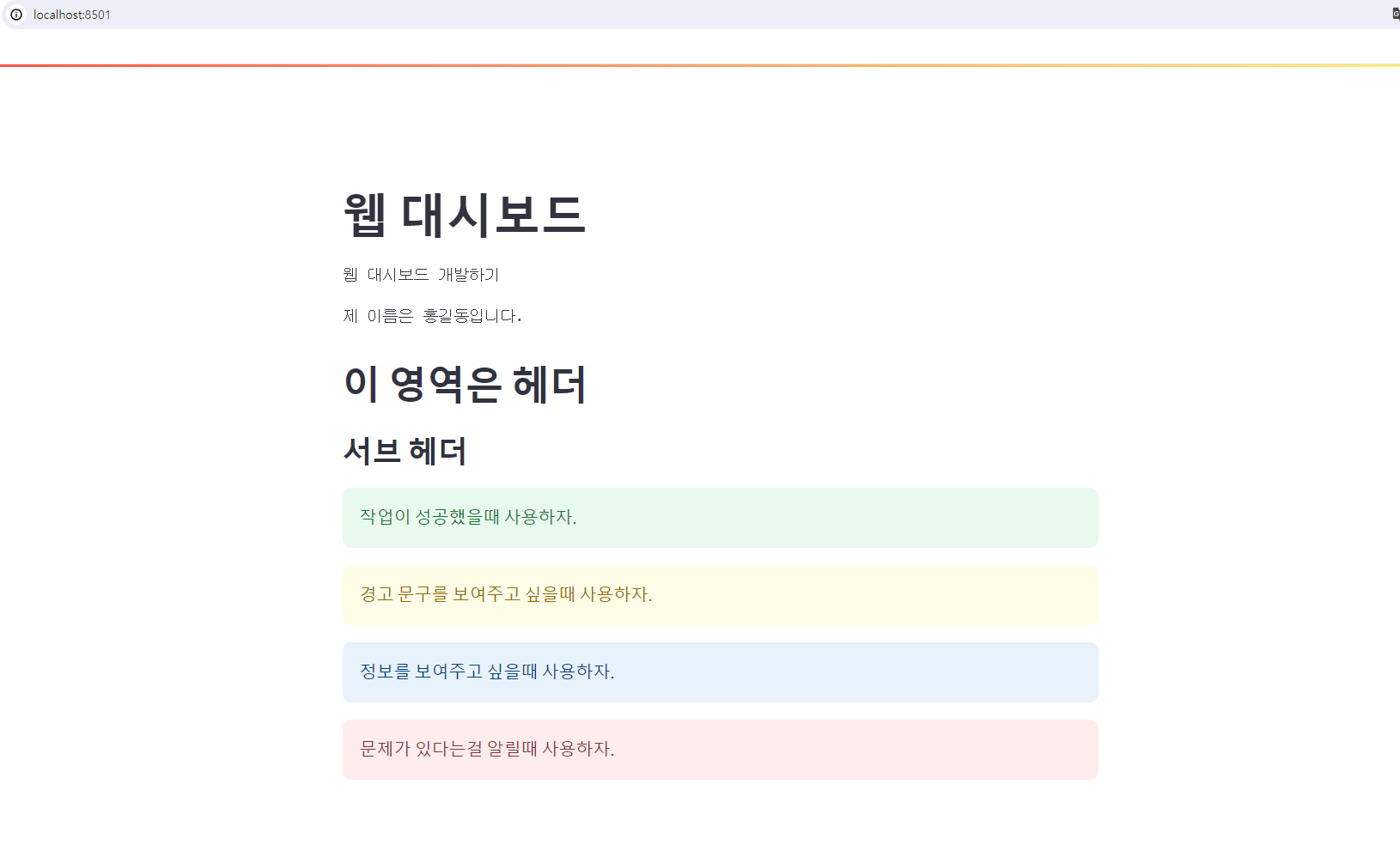
Python streamlit 에서 DataFrame 웹 화면에 표시 ▷ 실행# 판다스 데이터 프레임을 웹 화면에 보여주는 방법import streamlit as stimport pandas as pddef main() : df = pd.read_csv('./data/iris.csv') st.dataframe(df) # species 컬럼의 유니크 값을 화면에 표시 st.write(df['species'].unique()) st.text('아이리스 꽃은' + df['species'].unique() + '로 되어 있다.')if __name__ == '__main__' : main() ▶ 결과